
python 基础系列篇:三、认识函数、方法,以及学会调试
python 基础系列篇:三、认识函数、方法,以及学会调试
- 约定
- 内置函数
- 字符串相关
- 编码和解码
- 字符类型判断
- ⚠️ 使用任何函数,方法时,需要明确知道他的使用范围
- 💡 使用开发环境查依托于实例的函数、方法的帮助信息
- 字符串拼接及切割
- 字符串格式化
- 然后偷懒了,其他内置函数
- 学会看错误提示及调试
- 开发环境检查语法错误
- 运行时阅读报错信息
- 在开发环境中根据报错定位到错误位置
- ⚠️ 千万注意不要修改自己代码以外的内容
- 调试
- 结束语
约定
约定所有本文的读者,已经有了一定的python基础知识,知道了python的语法结构。如需补课,请参考老顾的前两篇系列文章《python 基础系列篇:一、基本语法与基础数据类型》《python 基础系列篇:二、输入输出,开始培养程序员的思想》。
约定,所有的读者老爷都有一颗认真的心,喜欢较真,毕竟当你使用计算机帮你工作的时候,他从来没有模糊的时候,对就是对,错就是错。程序员的世界很简单。
约定,文中出现的任何未讲解过的函数或方法,都可以自行在帮助窗口得到其信息。
约定,本系列文章不侧重算法,如有需要,可翻阅老顾的 leetcode 学习系列,里面不少算法题是老顾也没有见过的。该系列老顾以自身基础答题,中间有讲解思路及其代码演变过程。
约定,这是老顾最后一个约定,之后系列文章中不再有新的约定。
内置函数
在任何一门编程语言中,都包含了大量的方法、函数,以及各种各样的包(包含了更多的类、方法和函数的集合)。如果想要用好一门编程语言,则必须了解并清楚这些函数、方法的作用机制,使用范围。
我们先来认识几个简单的字符串函数。
字符串相关
编码和解码
首先,我们知道计算机是存储的2进制数据,所有我们可见的内容,都是通过各种转换得出来的,那么,字符也不例外,不过,如果直接显示二进制内容,则对大多数的人太不友好了,所以,我们把8位的二进制作为一个字节,也就是十进制的0到255,对应的就是 0000 0000 到 1111 1111,也就是十六进制的 00 到 FF。嗯,还是十进制最友好。那么就来认识一下字符转ASCII码的函数和他的逆函数。
print(ord('a')) # ord 将字符转成 ASCII 码
97
print(chr(65)) # 将数字转成对应 ASCII 码的字符
A
其实这么说有点狭隘了,他实际可以转成 unicode 码的,不过因为 unicode 码前256个和 8 位 ASCII 一致,所以大差不差的意思。
print(ord('张'))
24352
print(chr(48012))
뮌
print(chr(58012))
print(chr(24312))
廸
额,反正我是记不住 unicode 码,里面字符太特么多了,包括各种语言的字符,数学符号,音乐符号,甚至什么象棋、国际象棋符号之类的,总之,大部分有特定意义的符号,基本都在里面了。有兴趣的小伙伴可以围观下这里《Unicode编码范围》,咱也没验证过对不对,但大题的意思就是这个意思。
除了这些直接可用的数字外,我们可能会接收一些二进制的信息,或者需要发送一些二进制的信息,那么我们就需要用到 encode 和 decode 了。
'二次元纸片人'.encode('utf8')
Out[33]: b'\xe4\xba\x8c\xe6\xac\xa1\xe5\x85\x83\xe7\xba\xb8\xe7\x89\x87\xe4\xba\xba''二次元纸片人'.encode('gbk')
Out[34]: b'\xb6\xfe\xb4\xce\xd4\xaa\xd6\xbd\xc6\xac\xc8\xcb'b'\xe4\xba\x8c\xe6\xac\xa1\xe5\x85\x83\xe7\xba\xb8\xe7\x89\x87\xe4\xba\xba'.decode('utf8')
Out[35]: '二次元纸片人'
-------
b'\xe4\xba\x8c\xe6\xac\xa1\xe5\x85\x83\xe7\xba\xb8\xe7\x89\x87\xe4\xba\xba'.decode('gbk')
Traceback (most recent call last):File "C:\Users\sosome\AppData\Local\Temp\ipykernel_26248\3692504011.py", line 1, in | b'\xe4\xba\x8c\xe6\xac\xa1\xe5\x85\x83\xe7\xba\xb8\xe7\x89\x87\xe4\xba\xba'.decode('gbk')UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 4: illegal multibyte sequence
| 哦,最后一个报错了,因为不同的编码可以得到不同的二进制,但二进制数据解码的时候,需要按照原有的编码解码,如果不是,就很大概率出错,或者乱码了。在字符串前边加了一个修饰 b,则表示这里是二进制信息了。
a = '二次元纸片人'.encode('utf8')for i in a:print(i)
228
186
140
230
172
161
229
133
131
231
186
184
231
137
135
228
186
186
嗯,说的很高大上的样子,其实里面就是用二进制方式存放的数字罢了,你遍历下,他就露出原形了。
a = '二次元纸片人'.encode('utf8')
b = [n for n in a]
c = bytes(b)
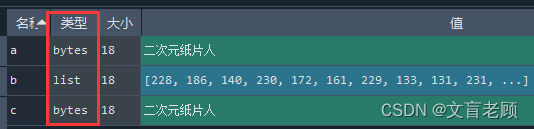
那么,我们很容易就可以将其转换成各种我们想要的形状了。
字符类型判断
在python中,提供了一系列的字符类型判断,在任意字符串之后可以用点的方式将其追加并返回判断结果,例如用 isalpha 来判断字符是不是字母。
''.isalpha()
Out[2]: False'1'.isalpha()
Out[3]: False'a'.isalpha()
Out[4]: True'ab'.isalpha()
Out[5]: True'a1b'.isalpha()
Out[6]: False
嗯,意思是这个意思,但是你所知道的就一定是准确的吗?
⚠️ 使用任何函数,方法时,需要明确知道他的使用范围
来看看一个小伙伴的问题。python凯撒密码加密
这个小伙伴的代码,总有一个加密解密是错的,为什么呢?老顾也很好奇,毕竟老顾自己习惯用正则判断了,这些类型判断函数也不是很熟悉,于是老顾就编写了一个小代码,来细细探究了一下,到底有哪些会出现异常。
fun = 'isalnum,isalpha,isascii,isdecimal,isdigit,isidentifier,islower,isnumeric,isprintable,isspace,istitle,isupper'.split(',')
dic = {k:[] for k in fun}for i in range(32,512):for k in fun:if eval('chr({}).{}()'.format(i,k)):dic[k].append(i)for k in dic:print('==>',k)print(''.join([chr(v) for v in dic[k]]))print()
==> isalnum
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzª²³µ¹º¼½¾ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿĀāĂ㥹ĆćĈĉĊċČčĎďĐđĒēĔĕĖėĘęĚěĜĝĞğĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴĵĶķĸĹĺĻļĽľĿŀŁłŃńŅņŇňʼnŊŋŌōŎŏŐőŒœŔŕŖŗŘřŚśŜŝŞşŠšŢţŤťŦŧŨũŪūŬŭŮůŰűŲųŴŵŶŷŸŹźŻżŽžſƀƁƂƃƄƅƆƇƈƉƊƋƌƍƎƏƐƑƒƓƔƕƖƗƘƙƚƛƜƝƞƟƠơƢƣƤƥƦƧƨƩƪƫƬƭƮƯưƱƲƳƴƵƶƷƸƹƺƻƼƽƾƿǀǁǂǃDŽDždžLJLjljNJNjnjǍǎǏǐǑǒǓǔǕǖǗǘǙǚǛǜǝǞǟǠǡǢǣǤǥǦǧǨǩǪǫǬǭǮǯǰDZDzdzǴǵǶǷǸǹǺǻǼǽǾǿ==> isalpha
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzªµºÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿĀāĂ㥹ĆćĈĉĊċČčĎďĐđĒēĔĕĖėĘęĚěĜĝĞğĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴĵĶķĸĹĺĻļĽľĿŀŁłŃńŅņŇňʼnŊŋŌōŎŏŐőŒœŔŕŖŗŘřŚśŜŝŞşŠšŢţŤťŦŧŨũŪūŬŭŮůŰűŲųŴŵŶŷŸŹźŻżŽžſƀƁƂƃƄƅƆƇƈƉƊƋƌƍƎƏƐƑƒƓƔƕƖƗƘƙƚƛƜƝƞƟƠơƢƣƤƥƦƧƨƩƪƫƬƭƮƯưƱƲƳƴƵƶƷƸƹƺƻƼƽƾƿǀǁǂǃDŽDždžLJLjljNJNjnjǍǎǏǐǑǒǓǔǕǖǗǘǙǚǛǜǝǞǟǠǡǢǣǤǥǦǧǨǩǪǫǬǭǮǯǰDZDzdzǴǵǶǷǸǹǺǻǼǽǾǿ==> isascii!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~==> isdecimal
0123456789==> isdigit
0123456789²³¹==> isidentifier
ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyzªµºÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿĀāĂ㥹ĆćĈĉĊċČčĎďĐđĒēĔĕĖėĘęĚěĜĝĞğĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴĵĶķĸĹĺĻļĽľĿŀŁłŃńŅņŇňʼnŊŋŌōŎŏŐőŒœŔŕŖŗŘřŚśŜŝŞşŠšŢţŤťŦŧŨũŪūŬŭŮůŰűŲųŴŵŶŷŸŹźŻżŽžſƀƁƂƃƄƅƆƇƈƉƊƋƌƍƎƏƐƑƒƓƔƕƖƗƘƙƚƛƜƝƞƟƠơƢƣƤƥƦƧƨƩƪƫƬƭƮƯưƱƲƳƴƵƶƷƸƹƺƻƼƽƾƿǀǁǂǃDŽDždžLJLjljNJNjnjǍǎǏǐǑǒǓǔǕǖǗǘǙǚǛǜǝǞǟǠǡǢǣǤǥǦǧǨǩǪǫǬǭǮǯǰDZDzdzǴǵǶǷǸǹǺǻǼǽǾǿ==> islower
abcdefghijklmnopqrstuvwxyzªµºßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿāăąćĉċčďđēĕėęěĝğġģĥħĩīĭįıijĵķĸĺļľŀłńņňʼnŋōŏőœŕŗřśŝşšţťŧũūŭůűųŵŷźżžſƀƃƅƈƌƍƒƕƙƚƛƞơƣƥƨƪƫƭưƴƶƹƺƽƾƿdžljnjǎǐǒǔǖǘǚǜǝǟǡǣǥǧǩǫǭǯǰdzǵǹǻǽǿ==> isnumeric
0123456789²³¹¼½¾==> isprintable!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõö÷øùúûüýþÿĀāĂ㥹ĆćĈĉĊċČčĎďĐđĒēĔĕĖėĘęĚěĜĝĞğĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴĵĶķĸĹĺĻļĽľĿŀŁłŃńŅņŇňʼnŊŋŌōŎŏŐőŒœŔŕŖŗŘřŚśŜŝŞşŠšŢţŤťŦŧŨũŪūŬŭŮůŰűŲųŴŵŶŷŸŹźŻżŽžſƀƁƂƃƄƅƆƇƈƉƊƋƌƍƎƏƐƑƒƓƔƕƖƗƘƙƚƛƜƝƞƟƠơƢƣƤƥƦƧƨƩƪƫƬƭƮƯưƱƲƳƴƵƶƷƸƹƺƻƼƽƾƿǀǁǂǃDŽDždžLJLjljNJNjnjǍǎǏǐǑǒǓǔǕǖǗǘǙǚǛǜǝǞǟǠǡǢǣǤǥǦǧǨǩǪǫǬǭǮǯǰDZDzdzǴǵǶǷǸǹǺǻǼǽǾǿ==> isspace==> istitle
ABCDEFGHIJKLMNOPQRSTUVWXYZÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞĀĂĄĆĈĊČĎĐĒĔĖĘĚĜĞĠĢĤĦĨĪĬĮİIJĴĶĹĻĽĿŁŃŅŇŊŌŎŐŒŔŖŘŚŜŞŠŢŤŦŨŪŬŮŰŲŴŶŸŹŻŽƁƂƄƆƇƉƊƋƎƏƐƑƓƔƖƗƘƜƝƟƠƢƤƦƧƩƬƮƯƱƲƳƵƷƸƼDŽDžLJLjNJNjǍǏǑǓǕǗǙǛǞǠǢǤǦǨǪǬǮDZDzǴǶǷǸǺǼǾ==> isupper
ABCDEFGHIJKLMNOPQRSTUVWXYZÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞĀĂĄĆĈĊČĎĐĒĔĖĘĚĜĞĠĢĤĦĨĪĬĮİIJĴĶĹĻĽĿŁŃŅŇŊŌŎŐŒŔŖŘŚŜŞŠŢŤŦŨŪŬŮŰŲŴŶŸŹŻŽƁƂƄƆƇƉƊƋƎƏƐƑƓƔƖƗƘƜƝƟƠƢƤƦƧƩƬƮƯƱƲƳƵƷƸƼDŽLJNJǍǏǑǓǕǗǙǛǞǠǢǤǦǨǪǬǮDZǴǶǷǸǺǼǾ
嗯,老顾较了下真,输出到512的字符集,结果重点一看 isalpha 那里行,好家伙,这么多字符都算字母。。。。嗯也没错,的确都是各种字母,不过。。。凯撒他认识的屁其他字母,他就认识26个字母。
然后看了看其他类型判断,好家伙,isdecimal 是纯数字,isdigit 就有小数字了,isnumeric 则连分数都有了。。。。
isspace 则更意外了,我一直以为只有两个空格,分别是 32 对应的常用空格,160对应的英文文档空格,这里居然又跑出来了个 133
for k in dic:print('==>',k)#print(''.join([chr(v) for v in dic[k]]))print(' '.join([str(v) for v in dic[k]])) # 改成数字输出即可看到一些不可见字符print()
所以说,不能知其然不知其所以然,总要对使用的东西进行一个深度了解才好。
💡 使用开发环境查依托于实例的函数、方法的帮助信息
嗯,再补充一个小知识点,有的小伙伴应该发现,这次的这些函数没有办法在帮助里查询到。因为这些方法是依托于类型实体的,所以我们在查这个帮助的时候,应该用 类型.函数 的方式来查。
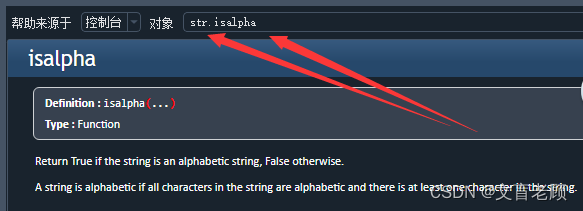
str 就是数据类型,然后用点调用的方法 isalpha ,就可以查到了。所以我第一篇文章要讲数据类型,否则你查资料都不会查。
字符串拼接及切割
上一篇文章里,其实老顾不小心用了个超纲的操作,就是字符串拼接的部分,不过也没超出太多,相信聪明的小伙伴们都已经学会操作了。老顾在这里再简单的提一下,及补充下切割就好。
先说简单的,字符串切割 split ,将字符串按照指定的分隔符切成一个列表
'张三,李四,王麻子'.split(',')
Out[6]: ['张三', '李四', '王麻子']' a bd efe aas wf awefaw fe '.split()
Out[7]: ['a', 'bd', 'efe', 'aas', 'wf', 'awefaw', 'fe']' a bd efe aas wf awefaw fe '.split(' ')
Out[8]:
['', '', '', '', 'a', 'bd', 'efe', 'aas', 'wf', 'awefaw', '', '', '', '', fe', '', '', '', '']
--
'a b c d fe e f e g a s'.split(maxsplit=3)
Out[10]: ['a', 'b', 'c', 'd fe e f e g a s']
--
' a bd efe aas wf awefaw fe '.split('')
Traceback (most recent call last):File "C:\Users\sosome\AppData\Local\Temp\ipykernel_4068\3662572163.py", line 1, in | ' a bd efe aas wf awefaw fe '.split('')ValueError: empty separator
| 在切分字符串的时候,切割符至少要指定一个长度为1的字符串,如果不指定,则 python 会帮忙处理空格,然后按空格切割,如果你指定了空格,效果不一定比不指定的好,可以比较两种情况。
注意数据类型,split 是针对字符串的操作,其他类型不一定支持哦(有些类会自己实现其内在的split,所以不能说所有非字符串对象都不支持split)。
那么,切割方法会了,拼接方法也就差不多会了
''.join(['abc','edf'])
Out[11]: 'abcedf'','.join(['abc','edf'])
Out[12]: 'abc,edf'' = '.join(['abc','edf'])
Out[13]: 'abc = edf'' = '.join({'a':'1','b':'2'})
Out[15]: 'a = b'' = '.join([1,2])
Traceback (most recent call last):File "C:\Users\sosome\AppData\Local\Temp\ipykernel_4068\3373094406.py", line 1, in | ' = '.join([1,2])TypeError: sequence item 0: expected str instance, int found
| 需要注意的是,join 函数内的参数,比如是可迭代的对象,即列表,集合词典元组之类的,且其类型必须是字符串,否则会报错哦
字符串格式化
然后就到了本文最重要的部分了,字符串格式化str.format
以及 f 修饰的字符串和 % 连接的字符串
a = 1
b = 2
c = 3
print('{} * {:2d} * {:2f} = {}'.format(a,b,c,a * b * c))
1 * 2 * 3.000000 = 6
print(f'{c:2f} * {b} * {a} = {a*b*c}')
3.000000 * 2 * 1 = 6
print('%.d * %.f * %.2f = %.2d'%(a,b,c,a*b*c))
1 * 2 * 3.00 = 06
z = {'x':a,'y':b,'z':c,'s':a*b*c}
print(f'{z["x"]:2f} * {z["y"]} * {a} = {a*b*c}')
1.000000 * 2 * 1 = 6
print('%(x).d * %(y).f * %(z).2f = %(s).2d'%(z))
1 * 2 * 3.00 = 06
三种方法都可以使用,也都可以内部修饰,具体返回也略有差异,根据习惯和用途进行选择即可。
然后偷懒了,其他内置函数
列表吗,那就是增删改查了,额。。。口误,说成数据库的了。。。
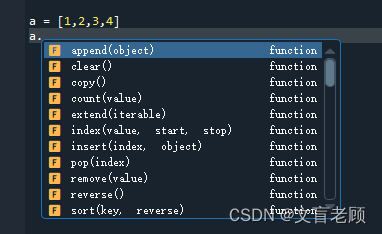
其实,耐心点,我们在开发环境里,对某类型的数据后边打个点,他就会出来好多提示,也就是这个类型所支持的函数和方法了
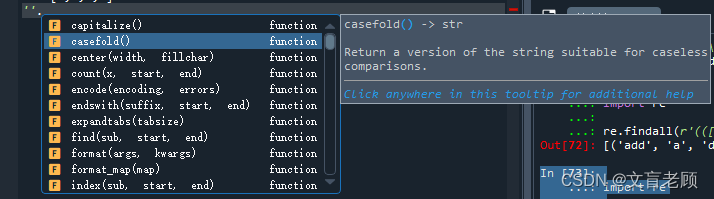
甚至还有更多的说明帮助信息。嗯这里也就不再一一讲解了。
学会看错误提示及调试
开发环境检查语法错误
在我们日常工作中,哪有不犯错的,越是老程序员,越是个bug接触的多,各种bug,各种意想不到的用户输入,各种千奇百怪的报错提示,不一而足
老顾在这几篇文章中,都会把一些错误的用法,以及他的错误提示放出来,就是希望大家能够重视起来。现在在csdn问答的很多小伙伴,经常就是一说什么什么程序报错,怎么修改?我哪知道怎么修改?看报错提示了啊。就和你去医院,上来和大夫就说,我头疼,我睡不着,大夫知道你是思春了还是肾虚了?那不得先看症状,然后一点点检查吗?
代码都是人手动打上去的,而开发环境非常友好的就会进行各种提示,避免你出现一些基本的错误。例如 spyder 这样的。

他自带了代码分析,你不用运行就知道这里有错误。这类错误通常是语法错误。这是最不应该保留到运行时期的错误(额。。其实老顾自己很多时候写的,都有一些语法错误,不过都是运行前修改,毕竟写代码也需要把思路码出来才能进行细致修改)。
运行时阅读报错信息
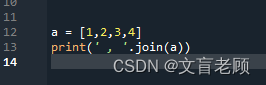
像这样的内容,则没有语法错误了,但是一运行,他就会报数据类型错误。

仔细阅读 XxxxError 之后的信息,看不懂扔到百度翻译里,你总会明白的知道自己哪里有错误。
在开发环境中根据报错定位到错误位置
相对来说,spyder 更友好的地方在于,点报错信息上边那个绿色的字部分: line 2 什么的,他会把光标定位到你出错的地方哦。
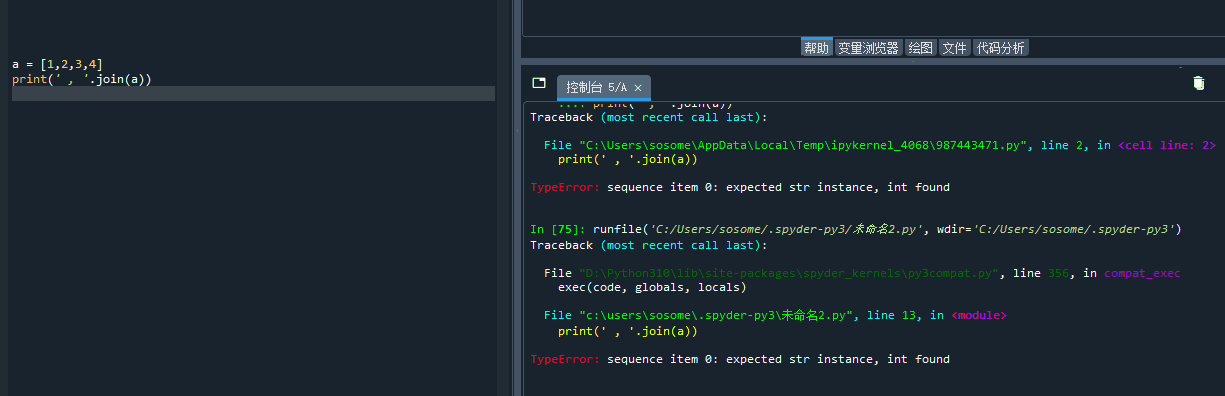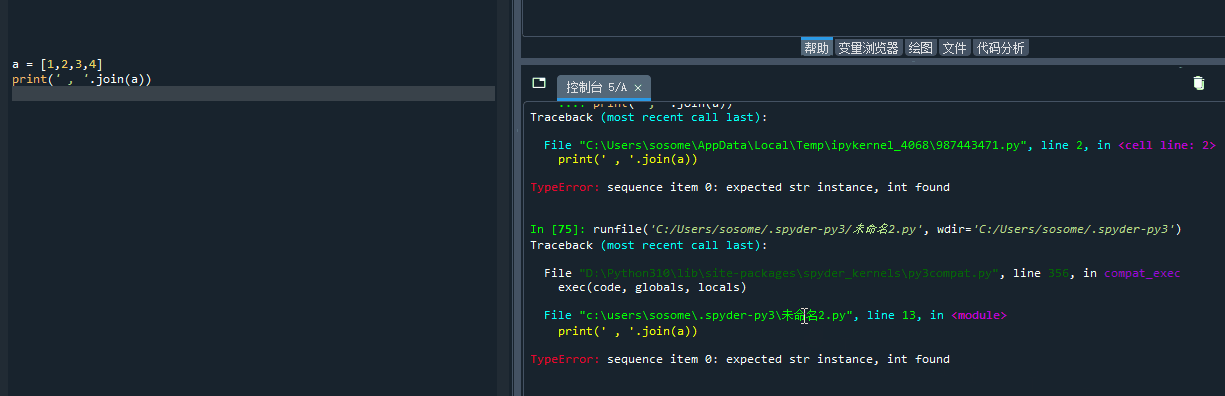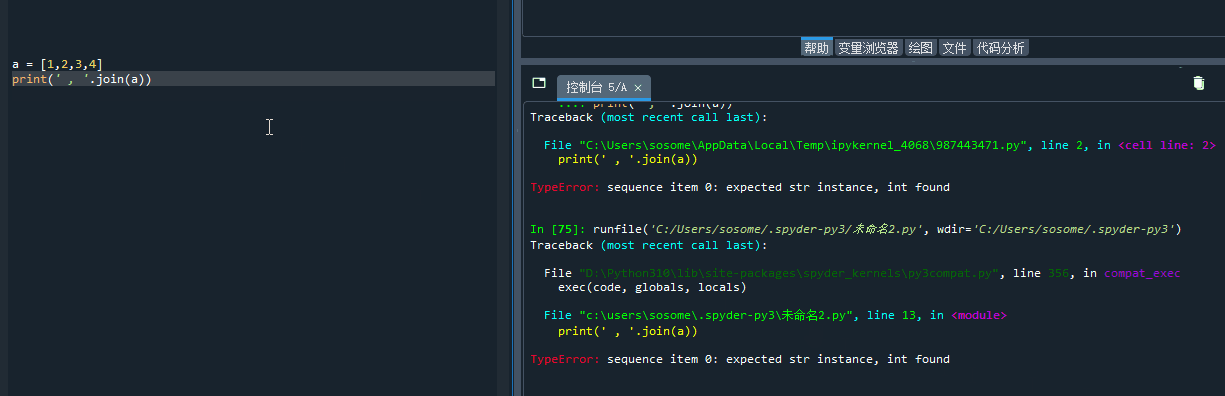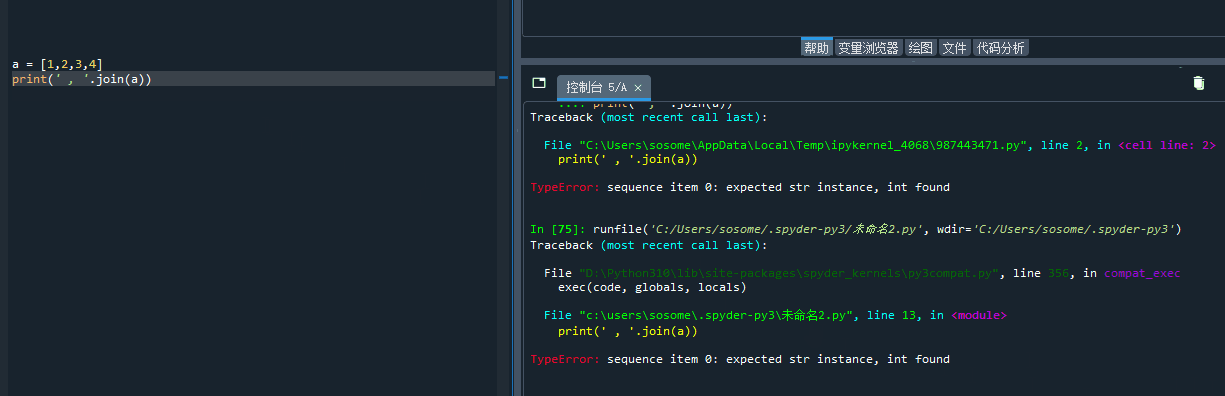
有了这样的帮手,你还怕你找不到哪里犯的错吗?
⚠️ 千万注意不要修改自己代码以外的内容
哦对了,不要点更过的报错提示,除了你自己代码中的内容,其他文件内容可千万不要修改啊亲。
比如我最后动画截图的这个,除了亮绿色的是我当前文件中的错误,还有暗绿色的,也可以定位过去。。。那是系统内置的运行文件。
这些内容太过复杂,你把握不住的。
调试
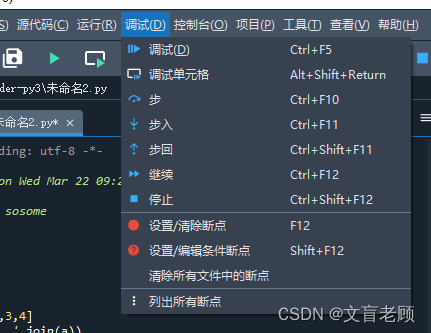
调试的意思很简单,就是允许在代码运行的过程中,在某些位置停留,等待开发人员处理,或者确认后再继续运行,或逐行运行。这么做,主要是用来观察在运行过程中,我们关注的数据变化是否符合预期。以便找到问题所在。目前在问答区出现的问题大多比较简单,还用不到调试模式。在大片代码的时候,如果产生了不符合预期的结果,那基本上都需要通过调试来确定到底是什么东西出了问题,才能找到解决方案了。
结束语
啊啊啊啊,终于写完这一篇了,小伙伴们应该已经学会使用开发环境和自我学习了吧。再后边,我们主要讲解一些其他基础知识了。语法、数据类型、函数什么的就不再细致的讲解了,我相信小伙伴们都是一通百通的天才。我们后边会慢慢偏如何将我们的想法变成代码,希望小伙伴们能继续阅读本系列文章。