
初探Flink
Flink的介绍
Flink项目环境准备
实现WordCount
Flink的介绍
Flink 起源于一个叫作 Stratosphere 的项目,它是由 3 所地处柏林的大学和欧洲其他一些大 学共同进行的研究项目,由柏林工业大学的教授沃克尔·马尔科(Volker Markl)领衔开发。2014 年 4 月,Stratosphere 的代码被复制并捐赠给了 Apache 软件基金会,Flink 就是在此基础上被 重新设计出来的。

发展历史
- 2014 年 8 月,Flink 第一个版本 0.6 正式发布(至于 0.5 之前的版本,那就是在 Stratosphere 名下的了)。与此同时 Fink 的几位核心开发者创办了 Data Artisans 公司, 主要做 Fink 的商业应用,帮助企业部署大规模数据处理解决方案。
- 2014 年 12 月,Flink 项目完成了孵化,一跃成为 Apache 软件基金会的顶级项目。
- 2015 年 4 月,Flink 发布了里程碑式的重要版本 0.9.0,很多国内外大公司也正是从这 时开始关注、并参与到 Flink 社区建设的。
- 2019 年 1 月,长期对 Flink 投入研发的阿里巴巴,以 9000 万欧元的价格收购了 Data Artisans 公司;之后又将自己的内部版本 Blink 开源,继而与 8 月份发布的 Flink 1.9.0 版本进行了合并。自此之后,Flink 被越来越多的人所熟知,成为当前最火的新一代 大数据处理框架。
由此可见,Flink 从真正起步到火爆,只不过几年时间。在这短短几年内,Flink 从最初的 第一个稳定版本 0.9,到目前本书编写期间已经发布到了 1.13.0,这期间不断有新功能新特性 加入。从一开始,Flink 就拥有一个非常活跃的社区,而且一直在快速成长。 Flink 的具体定位是:Apache Flink 是一个框架和分布式处理引擎。
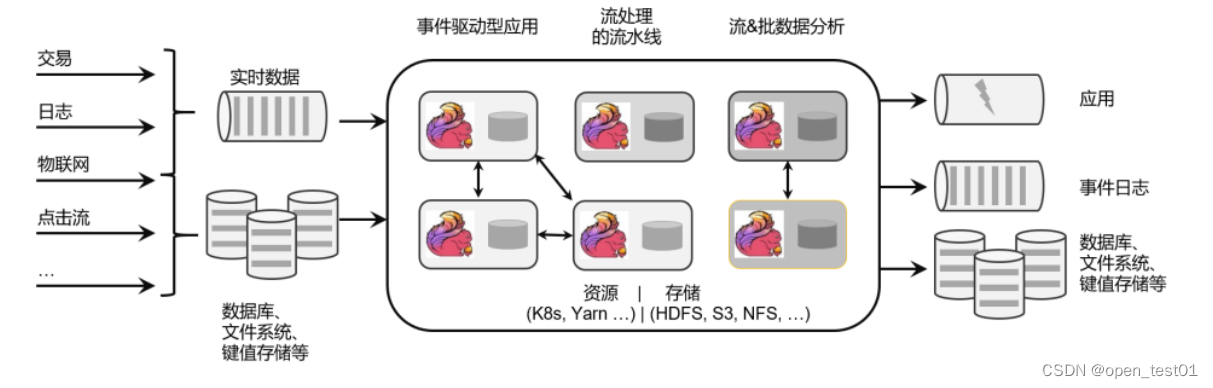
用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行 速度和任意规模来执行计算。
Flink项目环境准备
创建Maven
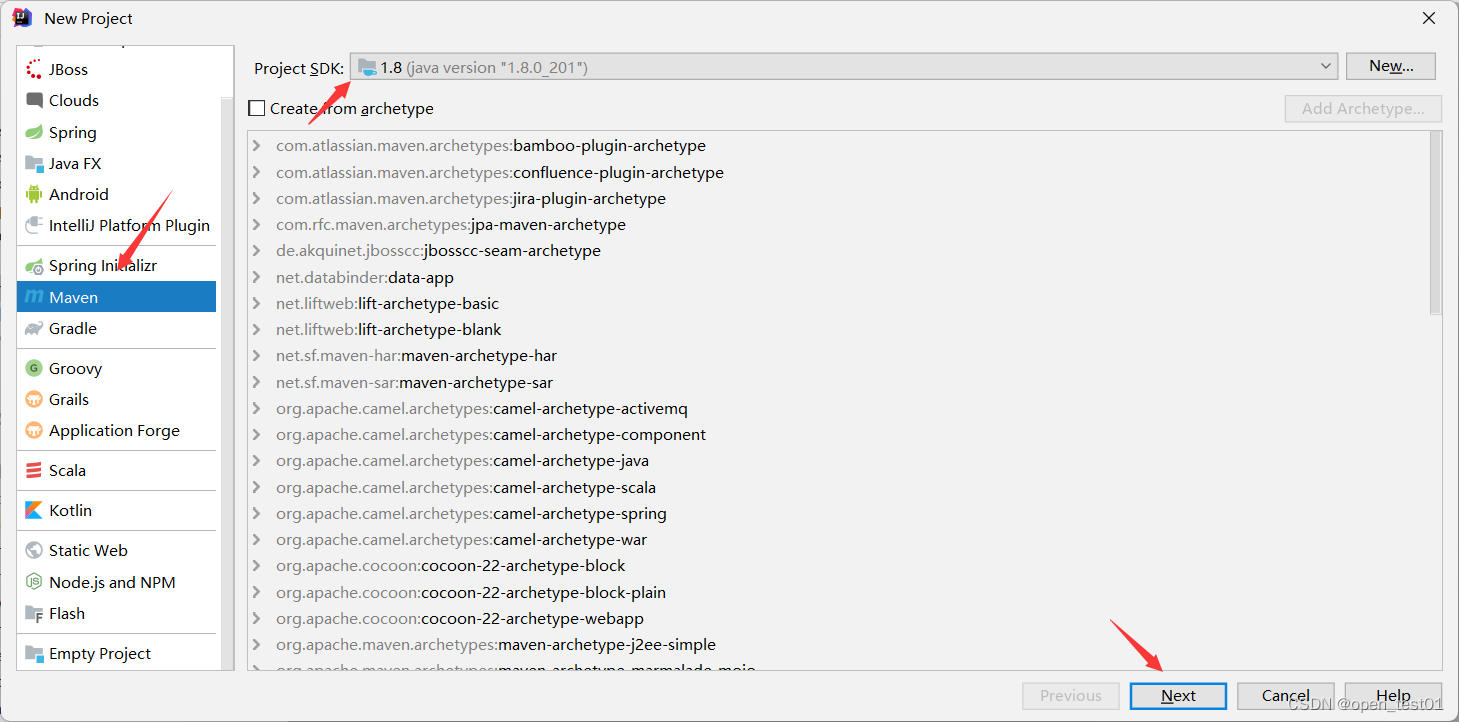
设置项目名称
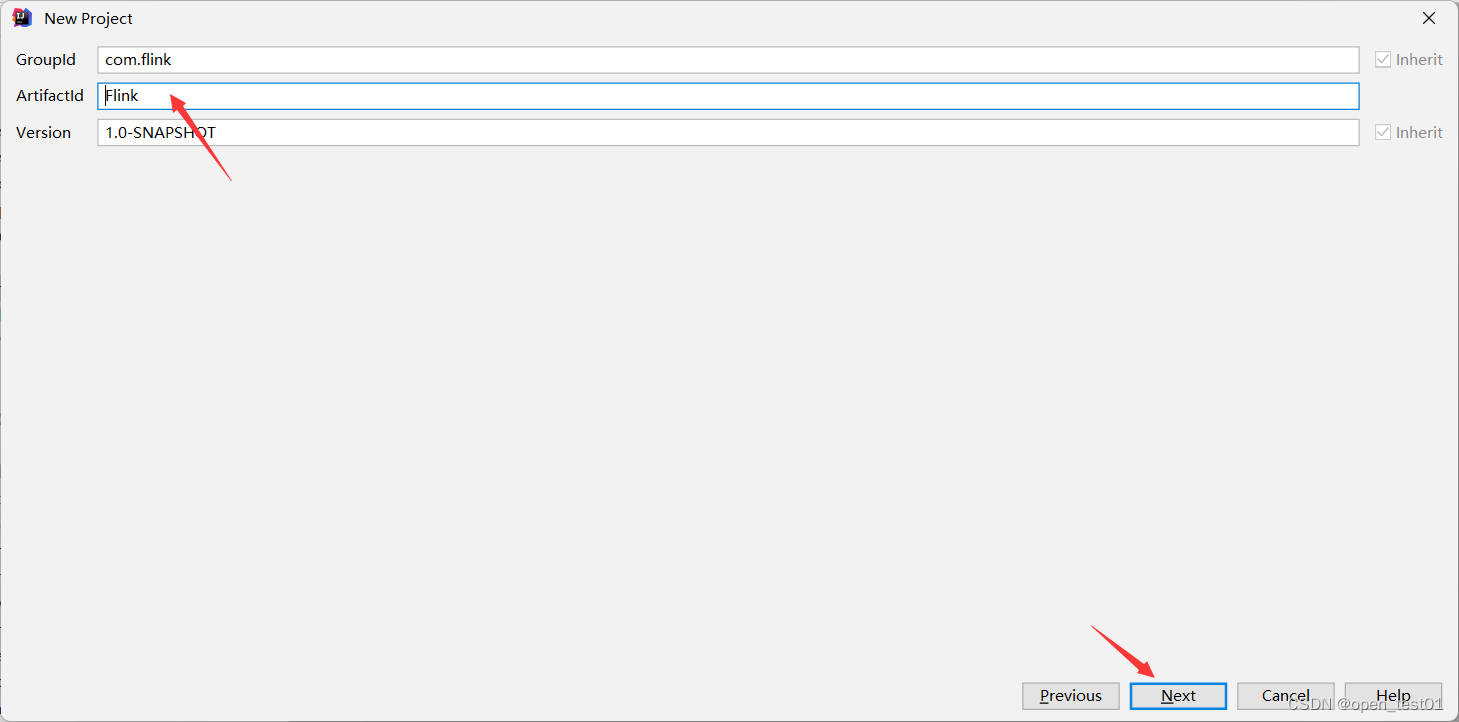
项目路径
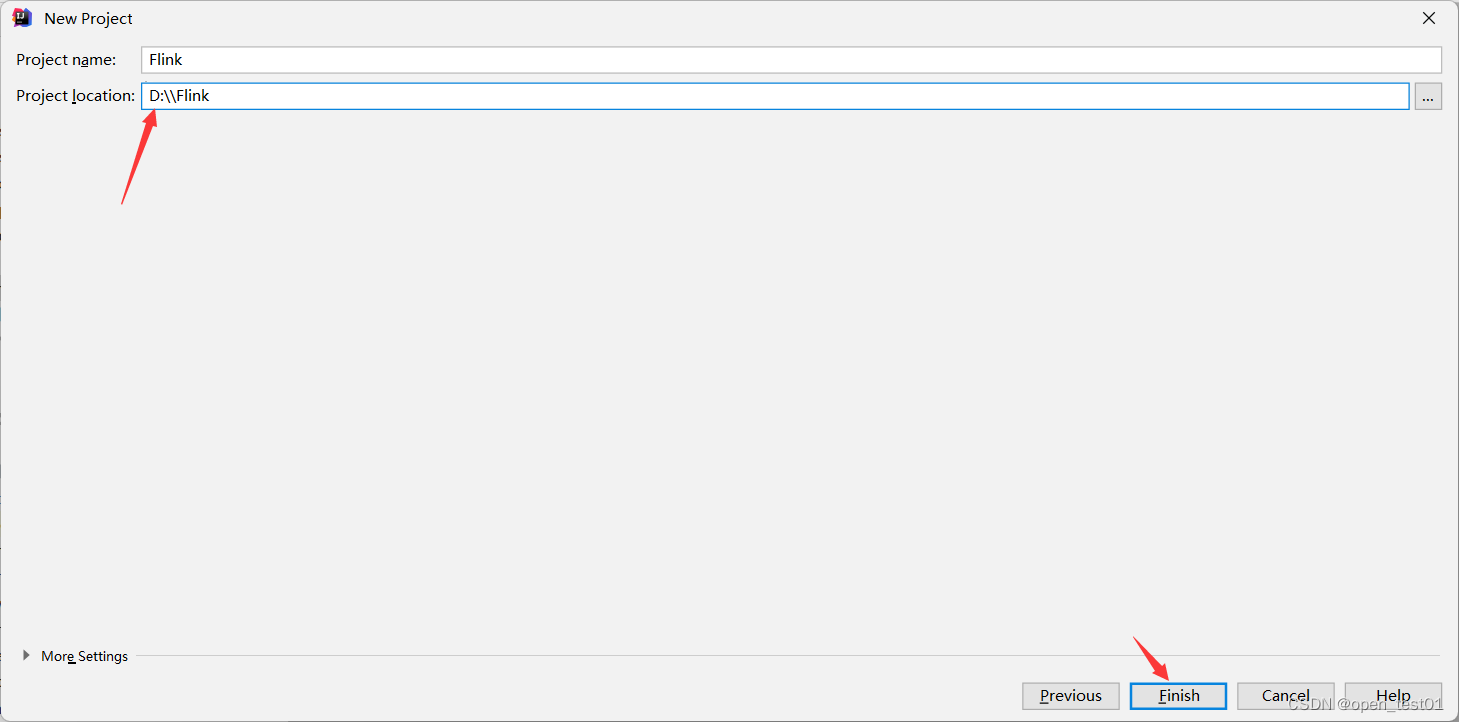
添加依赖
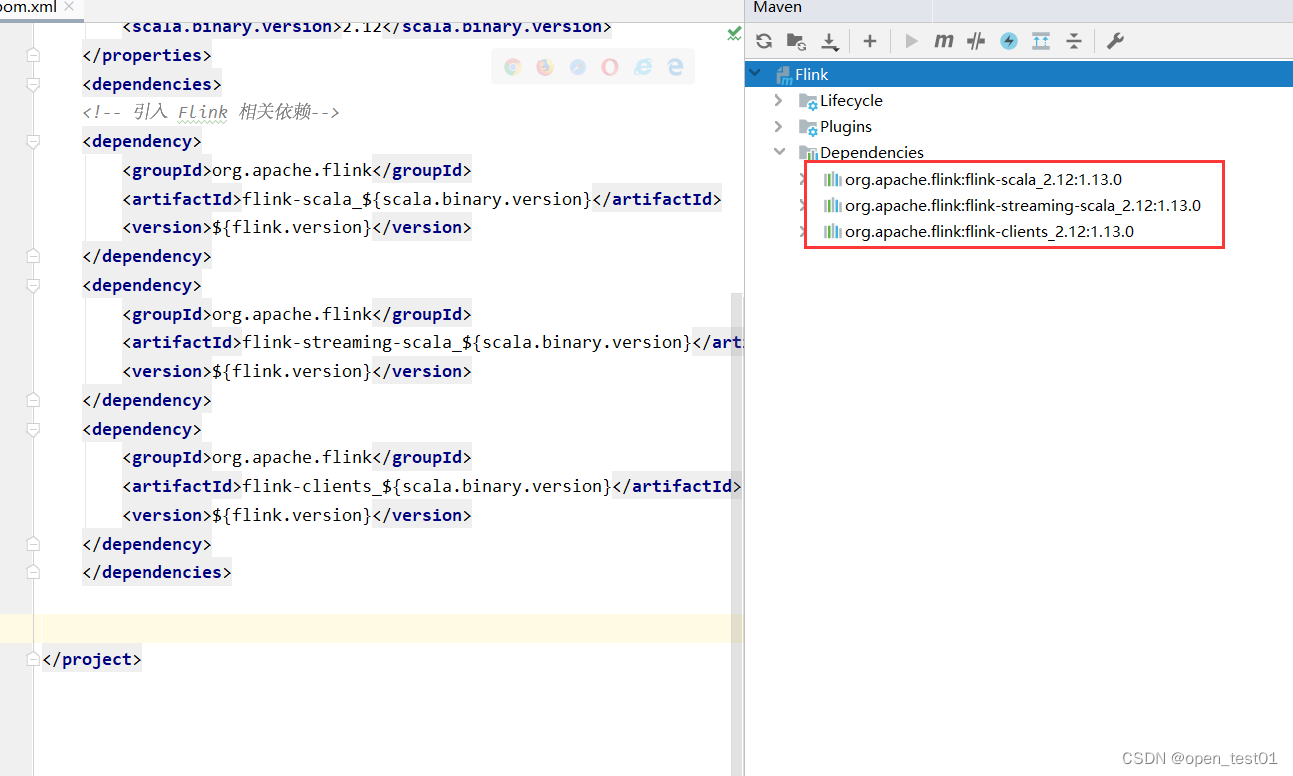
1.13.0 1.8 2.12 org.apache.flink flink-scala_${scala.binary.version} ${flink.version} org.apache.flink flink-streaming-scala_${scala.binary.version} ${flink.version} org.apache.flink flink-clients_${scala.binary.version} ${flink.version} 查看引入的依赖
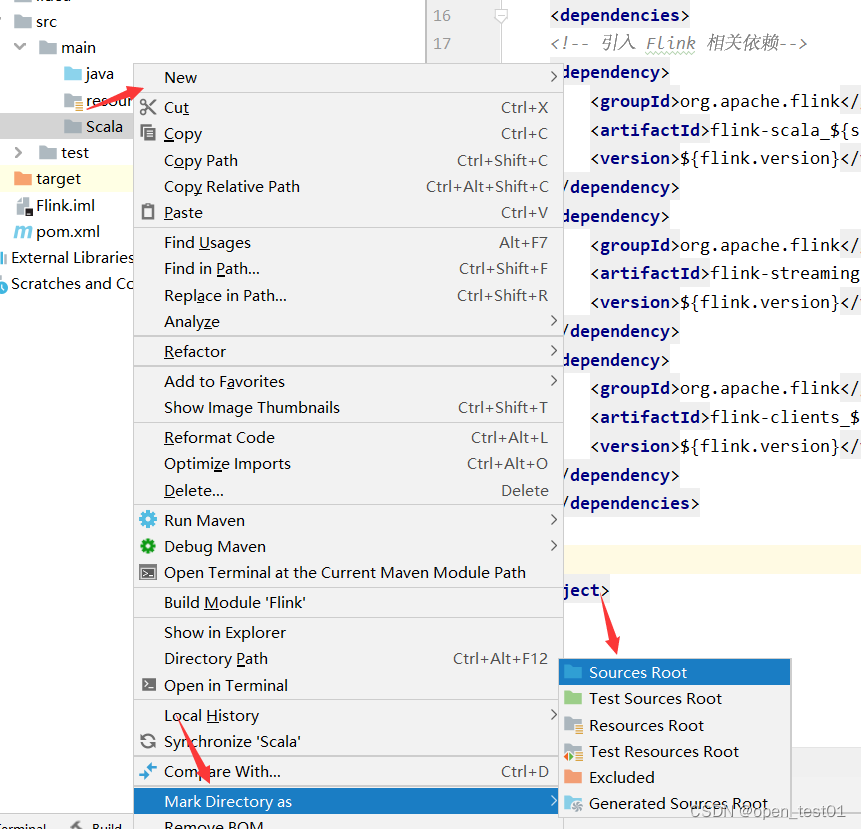
在main目录下新建一个Scala目录

将Scala目录设置为源代码目录
添加Scala支持

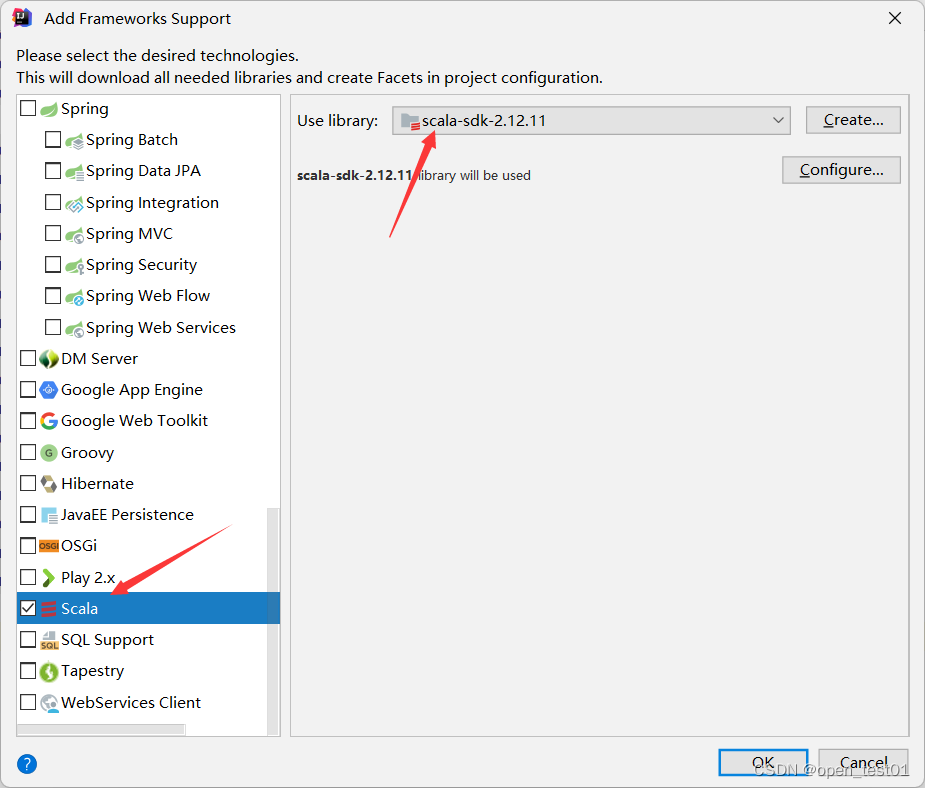
如果没有安装Scala的SDK的话参考链接:初探Scala_open_test01的博客-CSDN博客
实现WordCount
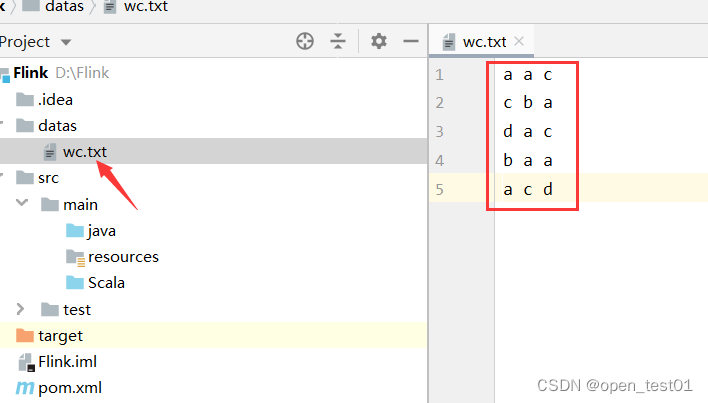
简单准备一个数据
批处理实现WordCount
def main(args: Array[String]): Unit = {//创建执行环境val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment//读取文件数据val line: DataSet[String] = env.readTextFile("datas\\wc.txt")//对数据集进行转换处理val value: DataSet[(String, Int)] = line.flatMap(_.split(" ")).map(word => (word,1))//分组val gpword: GroupedDataSet[(String, Int)] = value.groupBy(0) //按索引位置分组//聚合统计val rs: AggregateDataSet[(String, Int)] = gpword.sum(1)//索引位置累加聚合//输出rs.print()}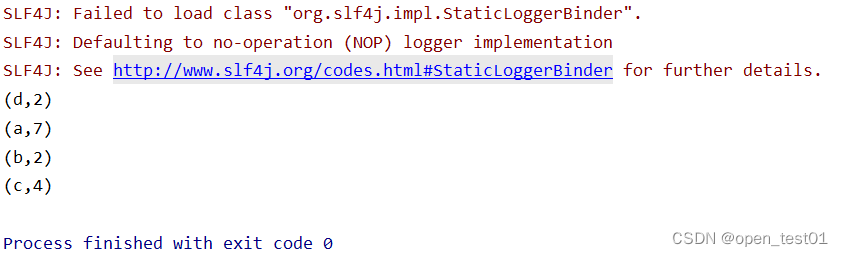
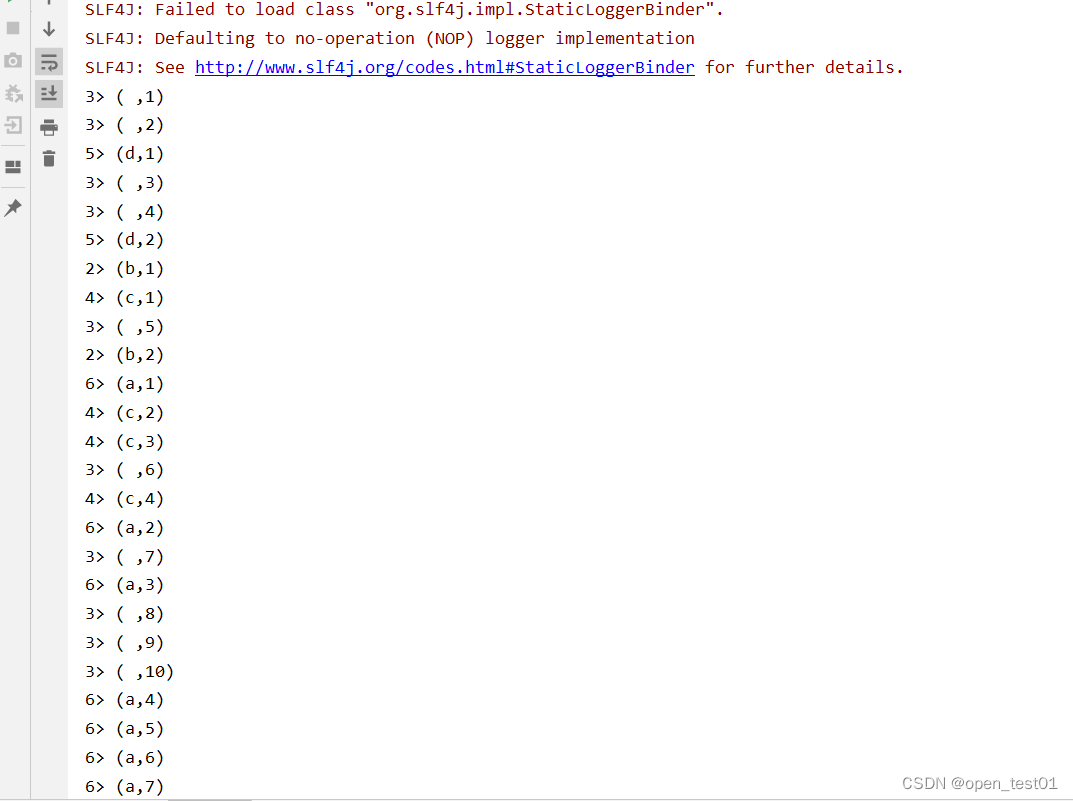
有界流处理实现WordCount
def main(args: Array[String]): Unit = {//创建执行环境val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment//读取文件数据val line: DataStream[String] = env.readTextFile("datas\\wc.txt")//对数据集进行转换处理val fl: DataStream[(String, Int)] = line.flatMap(_.split("")).map(w => (w,1))//分组val gp: KeyedStream[(String, Int), String] = fl.keyBy(_._1)//聚合统计val rs: DataStream[(String, Int)] = gp.sum(1)//输出rs.print()//执行当前任务env.execute()}我们可以看到,这与批处理的结果是完全不同的。批处理针对每个单词,只会输出一个最 终的统计个数;而在流处理的打印结果中,“a”这个单词每出现一次,都会有一个频次统计 数据输出。这就是流处理的特点,数据逐个处理,每来一条数据就会处理输出一次。我们通过 打印结果,可以清晰地看到单词“a”数量增长的过程。
无界流处理实现WordCount
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需 要保持一个监听事件的状态,持续地处理捕获的数据。
def main(args: Array[String]): Unit = {//创建执行环境val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment//读取socket文本流数据//socketTextStream("主机名","端口号")val line: DataStream[String] = env.socketTextStream("master",7496)//对数据集进行转换处理val fl: DataStream[(String, Int)] = line.flatMap(_.split("")).map(w => (w,1))//分组val gp: KeyedStream[(String, Int), String] = fl.keyBy(_._1)//聚合统计val rs: DataStream[(String, Int)] = gp.sum(1)//输出rs.print()//执行当前任务env.execute()}